1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
| import requests
import os
from moviepy.editor import VideoFileClip, AudioFileClip
import re
url = input("请输入 Bilibili 视频的网址:\n ")
def extract_bv(url):
"""
从给定的 URL 中提取 Bilibili 的 BV 号。
参数:
url (str): 包含 BV 号的 URL。
返回:
str: 提取到的 BV 号,如果未找到则返回 None。
"""
bv_pattern = r"BV[0-9A-Za-z]+"
match = re.search(bv_pattern, url)
if match:
return match.group(0)
else:
return None
bvid = extract_bv(url)
def find_api_inf(url, bvid, headers):
response = requests.get(url, headers=headers)
if response.status_code == 200:
html_content = response.text
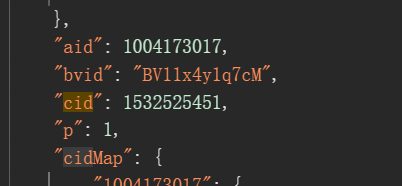
matches = re.findall(r'"aid":(\d+),"bvid":"(BV[0-9A-Za-z]+)","cid":(\d+)', html_content)
for aid, matched_bvid, cid in matches:
if matched_bvid == bvid:
return aid, cid
else:
print(f"未找到指定的 bvid: {bvid}")
else:
print(f"请求失败,状态码:{response.status_code}")
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
}
aid, cid = find_api_inf(url, bvid, headers)
params = {
"fnver": "0",
"fnval": "4048",
"fourk": "1",
"aid": aid,
"bvid": bvid,
"cid": cid,
}
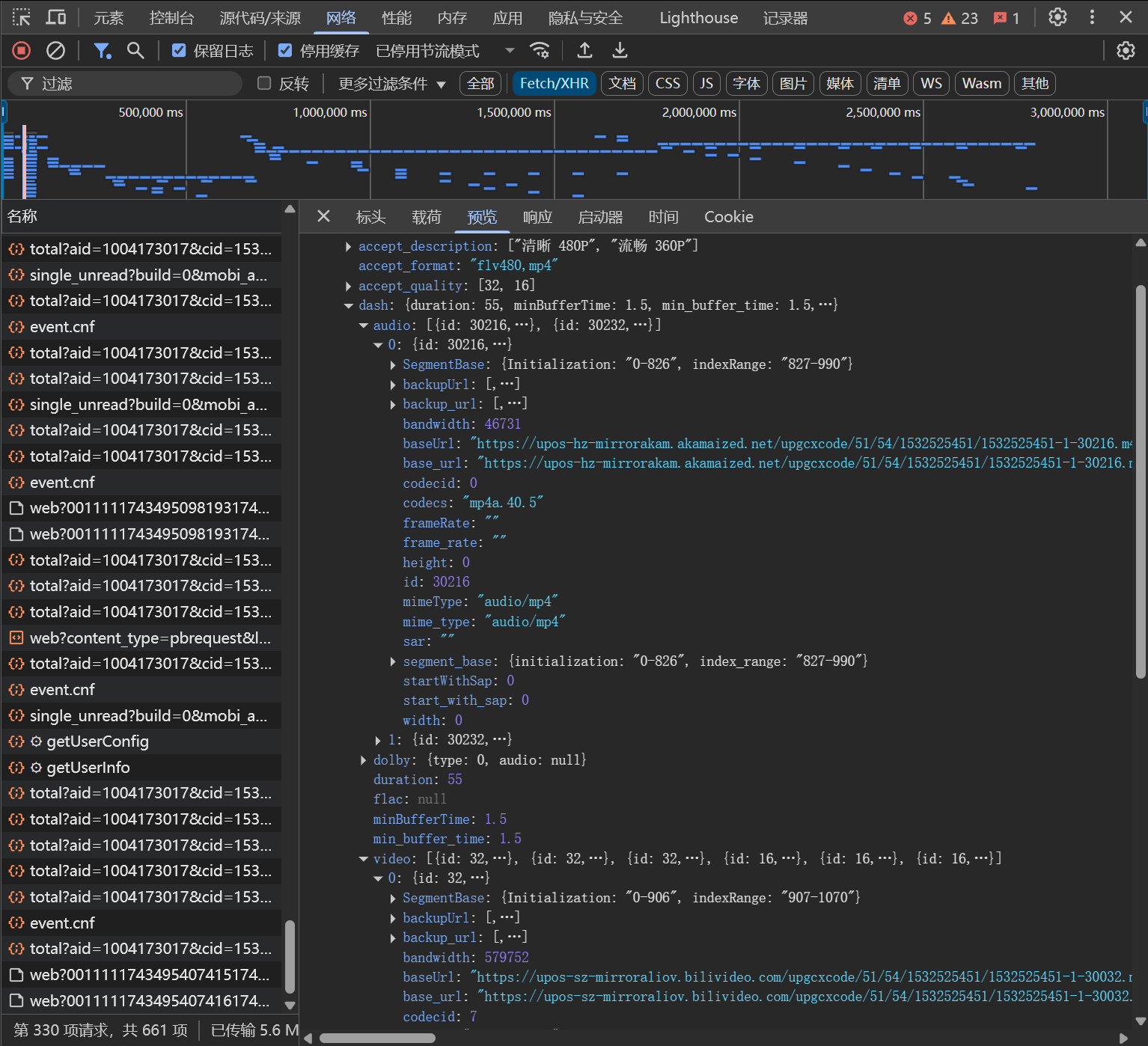
response = requests.get("https://api.bilibili.com/x/player/playurl", params=params, headers=headers)
data = response.json()
video_base_urls = []
audio_base_urls = []
for video_data in data['data']['dash']['video']:
if 'baseUrl' in video_data:
video_base_urls.append(video_data['baseUrl'])
if 'base_url' in video_data:
video_base_urls.append(video_data['base_url'])
for audio_data in data['data']['dash']['audio']:
if 'baseUrl' in audio_data:
audio_base_urls.append(audio_data['baseUrl'])
if 'base_url' in audio_data:
audio_base_urls.append(audio_data['base_url'])
def download_file(url, filename):
try:
print(f"正在下载: {url}")
response = requests.get(url, stream=True)
response.raise_for_status()
with open(filename, "wb") as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f"下载完成: {filename}")
return True
except Exception as e:
print(f"下载失败: {url}, 错误: {e}")
return False
video_file = "video.mp4"
audio_file = "audio.m4a"
video_downloaded = False
audio_downloaded = False
for video_url in video_base_urls:
if download_file(video_url, video_file):
video_downloaded = True
break
for audio_url in audio_base_urls:
if download_file(audio_url, audio_file):
audio_downloaded = True
break
if video_downloaded and audio_downloaded:
output_file = "output.mp4"
print("正在合并音频和视频...")
try:
video = VideoFileClip(video_file)
audio = AudioFileClip(audio_file)
video = video.set_audio(audio)
video.write_videofile(output_file, codec="libx264", audio_codec="aac")
print(f"合并完成: {output_file}")
except Exception as e:
print(f"合并失败: {e}")
finally:
video.close()
audio.close()
else:
print("视频或音频下载失败,无法合并。")
if os.path.exists(video_file):
os.remove(video_file)
if os.path.exists(audio_file):
os.remove(audio_file)
|